Automated Theorem Proving (ATP) in formal languages is a foundational challenge for AI. While recent Large Language Models (LLMs) have driven remarkable progress on benchmarks like miniF2F, they still fail on complex, competition-level problems such as those from the International Mathematical Olympiad (IMO). We argue this failure stems from a fundamental flaw in the prevailing training paradigm for state-of-the-art provers. These models are typically fine-tuned with reinforcement learning using only the binary success or failure of generated code as a reward signal. This approach neglects the quality of the underlying reasoning, encouraging models to develop degenerate strategies that over-rely on simple, built-in tactics rather than learning deep mathematical insight. To address this, we propose a novel framework that decouples high-level reasoning from low-level proof generation. Our approach utilizes two distinct, specialized models: a powerful, general-purpose Reasoner to generate diverse, strategic subgoal lemmas, and an efficient Prover to rigorously verify them. Only the verified lemmas are then used to construct the final proof. This modular design explicitly rewards high-quality problem decomposition and bypasses the pitfalls of end-to-end training. We evaluate our method on a challenging set of post-2000 IMO problems, a problem set on which no prior open-source prover has reported success. Our decoupled framework successfully solves 5 of these problems, demonstrating a significant step towards automated reasoning on exceptionally difficult mathematical challenges.
Our methodology is founded on the principle of decoupling high-level strategic reasoning from low-level formal proof generation. This separation allows us to use the best tool for each task: a powerful, general-purpose reasoning model for strategic decomposition, and a specialized, efficient theorem prover for formal verification. The workflow consists of three main stages:
We leverage a powerful, general-purpose LLM (e.g., Gemini 1.5 Pro) as a dedicated Reasoner. Its sole responsibility is to generate strategic subgoals (lemmas) by decomposing the main theorem. This focuses the model on its core strength—strategic thinking—while avoiding the complexities of full proof generation.
This stage acts as a critical filter. We employ a dedicated Prover model (e.g., DeepSeek-Prover-v2) to attempt to prove each candidate lemma generated in Stage 1. Only logically sound and verifiable lemmas are passed to the final stage. This grounds the Reasoner's creativity in formal rigor.
In the final stage, the prover tackles the main theorem, now armed with a set of verified lemmas. These lemmas are prepended to the context, transforming the original, monolithic proof task into a more tractable one of assembling a final proof from these powerful, pre-proven building blocks.
We evaluate our approach on a challenging benchmark of non-geometry IMO problems from 2000 to 2024. To the best of our knowledge, no existing open-source automated theorem prover has reported success on any problem from this set. In a stark demonstration of its effectiveness, our framework successfully solves 7 of these problems:
This marks a significant step towards automated reasoning on exceptionally difficult mathematical challenges.
A central hypothesis of our work is that fine-tuning LLMs for formal proving using only verifiable success as a reward (RLVR) can degrade their intrinsic mathematical reasoning. We tested this by comparing a specialized prover (\texttt{Kimina-Prover-7B}) with its general-purpose base model (\texttt{Qwen2.5-Math-7B}) on standard math benchmarks.
The results clearly show that the specialized prover's performance drops significantly on general math reasoning tasks, confirming that specialization for formal proofs comes at a cost. This finding strongly motivates our decoupled approach, which preserves the full reasoning capacity of a general-purpose model for high-level strategy.
| Model | Pass@1 Accuracy | |
|---|---|---|
| MATH | AIME24 | |
Qwen2.5-Math-7B-Instruct (Base Model) |
83.6% | 16.7% |
Kimina-Prover-Preview-Distill-7B (Prover) |
78.7% | 11.0% |
| Performance Drop (pts) | -4.9 | -5.7 |
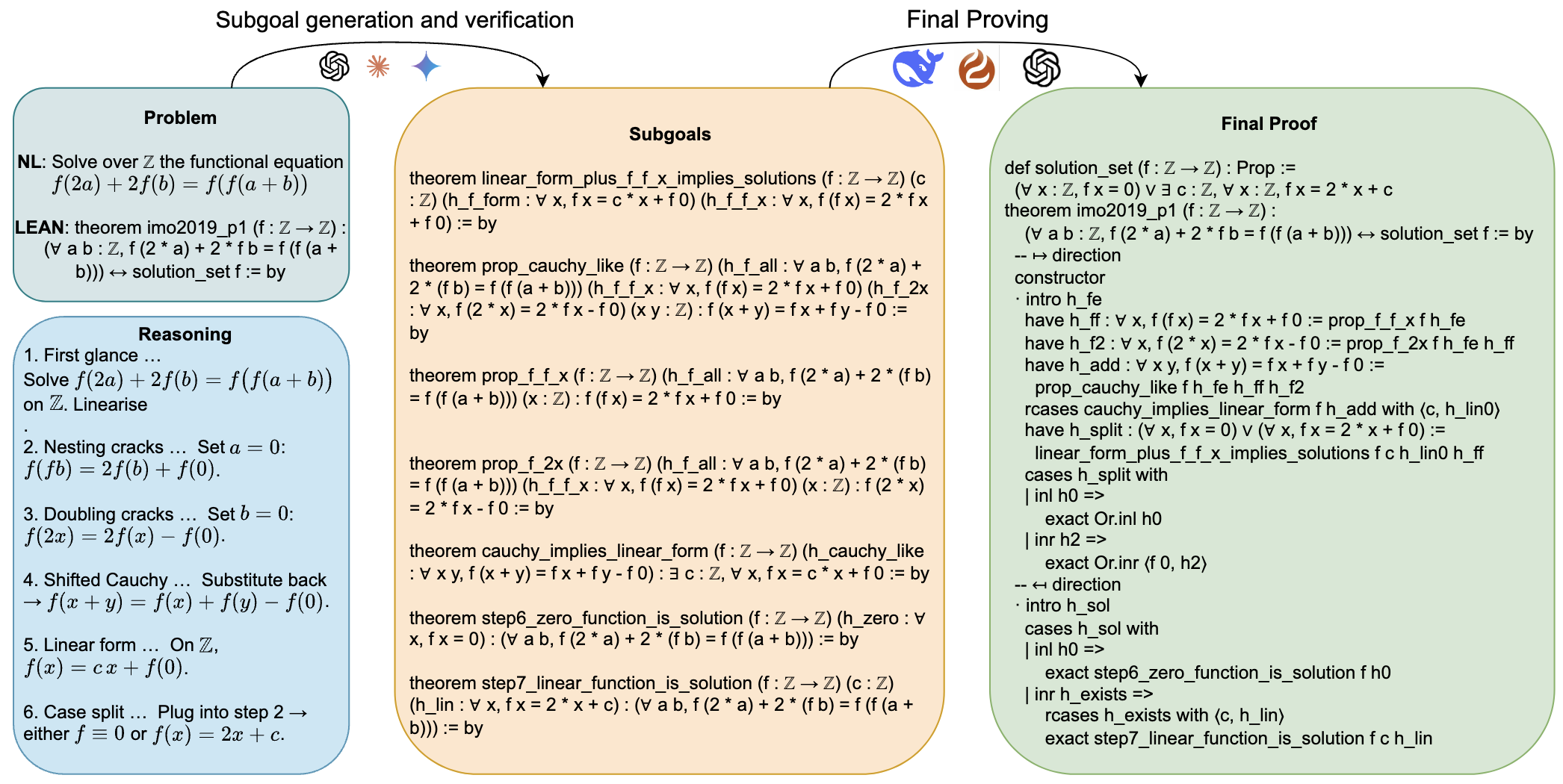
Below is the full, machine-generated proof for IMO 2019 Problem 1, as constructed by our framework. The proof is composed of several strategic lemmas (e.g., `prop_f_f_x`, `prop_f_2x`, `prop_cauchy_like`) that were first proposed by the Reasoner and then formally proven by the Prover. These verified lemmas were then used to construct the final proof of the main theorem.
-- Solution to IMO 2019 P1
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
def solution_set (f : ℤ → ℤ) : Prop :=
(∀ x : ℤ, f x = 0) ∨ ∃ c : ℤ, ∀ x : ℤ, f x = 2 * x + c
theorem prop_f_f_x (f : ℤ → ℤ) (h_f_all : ∀ a b, f (2 * a) + 2 * (f b) = f (f (a + b))) (x : ℤ) :
f (f x) = 2 * f x + f 0 := by
have h1 := h_f_all x 0
have h2 := h_f_all 0 x
omega
theorem prop_f_2x (f : ℤ → ℤ) (h_f_all : ∀ a b, f (2 * a) + 2 * (f b) = f (f (a + b)))
(h_f_f_x : ∀ x, f (f x) = 2 * f x + f 0) (x : ℤ) :
f (2 * x) = 2 * f x - f 0 := by
have h1 : f (f (2 * x)) = 2 * f (2 * x) + f 0 := by
exact h_f_f_x (2 * x)
have h2 : f (2 * x) + 2 * f x = f (f (2 * x)) := by
have h_inst := h_f_all x x
ring_nf at h_inst
exact h_inst
rw [h2] at h1
linarith
-- ... (and so on, additional proven lemmas would go here)
-- For brevity, showing the final proof structure
theorem imo2019_p1
(f : ℤ → ℤ) :
(∀ a b : ℤ, f (2 * a) + 2 * f b = f (f (a + b))) ↔ solution_set f := by
constructor
· intro h_fe
have h_ff : ∀ x, f (f x) = 2 * f x + f 0 :=
prop_f_f_x f h_fe
have h_f2 : ∀ x, f (2 * x) = 2 * f x - f 0 :=
prop_f_2x f h_fe h_ff
have h_add : ∀ x y, f (x + y) = f x + f y - f 0 :=
prop_cauchy_like f h_fe h_ff h_f2
rcases cauchy_implies_linear_form f h_add with ⟨c, h_lin0⟩
have h_split :
(∀ x, f x = 0) ∨ (∀ x, f x = 2 * x + f 0) :=
linear_form_plus_f_f_x_implies_solutions f c h_lin0 h_ff
cases h_split with
| inl h0 =>
exact Or.inl h0
| inr h2 =>
exact Or.inr ⟨f 0, h2⟩
· intro h_sol
cases h_sol with
| inl h0 =>
exact step6_zero_function_is_solution f h0
| inr h_exists =>
rcases h_exists with ⟨c, h_lin⟩
exact step7_linear_function_is_solution f c h_lin
@article{liang2024decoupling,
title={Towards Solving More Challenging IMO Problems via Decoupled Reasoning and Proving},
author={Liang, Zhenwen and Song, Linfeng and Li, Yang and Yang, Tao and Zhang, Feng and Mi, Haitao and Yu, Dong},
journal={arXiv preprint},
year={2025},
archivePrefix={arXiv},
}